Why Your AI Pilots Keep Dying — And the 4 Conditions That Must Be True Before You Scale
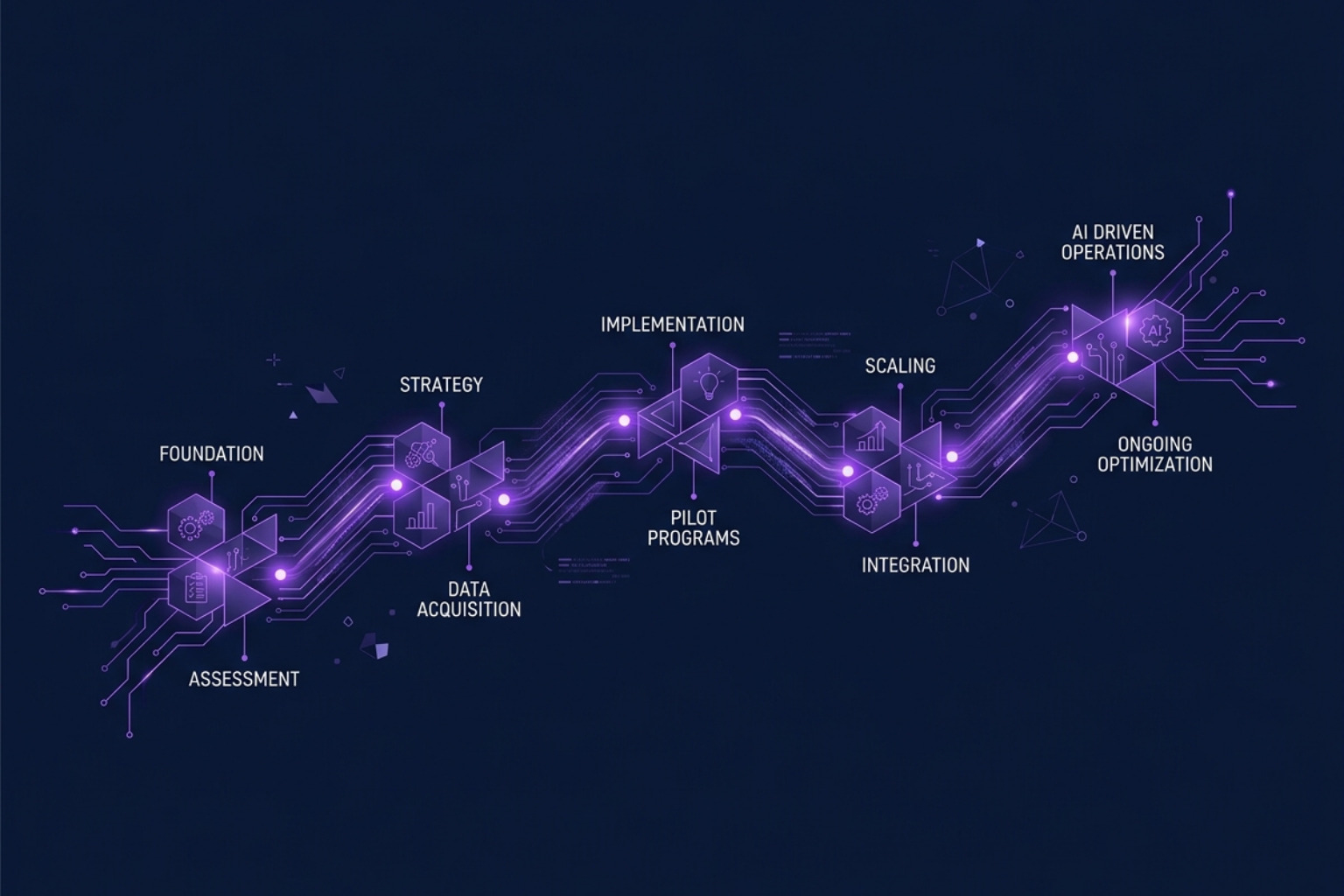
An AI transformation roadmap guides your organization from experimentation to embedded AI capability. This step-by-step framework covers readiness assessment, pilot selection, scaling, and governance.
Here's what I keep seeing: a company runs an AI pilot. It works. Leadership gets excited. They fund a "scale-up phase." Six months later, the pilot is dead, the team is demoralized, and the CFO is asking pointed questions about the seven-figure line item that produced nothing measurable.
The usual post-mortem blames execution. The vendor wasn't right. The data was dirty. The team lacked skills. These are symptoms, not causes.
The actual problem is structural. Most organizations attempt to scale AI before four preconditions are met. Skip any one of them and your pilot will produce impressive demos, enthusiastic Slack messages, and zero durable business impact.
I'm not going to walk you through Gartner's seven workstreams or McKinsey's maturity model. Those frameworks describe what AI adoption looks like from the outside. They don't tell you why yours isn't working from the inside.
What follows is a diagnostic. Four conditions that must be true — simultaneously — before any AI initiative survives first contact with organizational reality.
The Pilot Graveyard Pattern
Before we get to the conditions, let's name the pattern clearly.
A typical AI pilot lives in a protected environment. It has executive sponsorship. A dedicated team. Clean data (or at least a curated subset). Relaxed timelines. Minimal integration requirements. These conditions allow the pilot to succeed on its own terms.
Then someone says "scale it." Which means: integrate it into existing workflows, run it on production data, make it work for people who didn't volunteer for it, measure it against existing KPIs, and do all of this without the air cover that made the pilot possible.
The pilot dies not because the technology failed but because the organization wasn't ready to receive it. The gap between "this works in a sandbox" and "this works in our company" is not a technology gap. It's an organizational design gap.
Every failed scale-up I've observed — across CPG brands, DTC companies, B2B SaaS, and agencies — traces back to at least one of the four conditions being absent.
Condition 1: Decision Proximity
The AI must live where decisions are made, not where data is stored.
Most organizations place AI initiatives inside their data or engineering teams. This makes intuitive sense — those teams understand the technology. But it creates a fatal distance between the AI's output and the person who needs to act on it.
Consider a marketing org that builds a predictive model for campaign performance. The model lives in the data team's environment. It produces a weekly report. That report goes to the marketing director. The director interprets it, decides whether to adjust spend, then communicates the decision to the media buyer, who makes the change two days later.
By the time the AI's insight becomes action, the conditions have changed. The feedback loop is too slow to learn. The AI never improves because it never sees the consequences of its own recommendations in real time.
What Decision Proximity Actually Looks Like
The AI must be embedded in the workflow of the person making the decision — not reporting to them, but integrated into their tools, their cadence, their moment of choice.
- Wrong: A dashboard that shows AI-generated recommendations once a week.
- Right: An AI layer inside the campaign management tool that suggests reallocation at the moment the buyer is adjusting bids.
- Wrong: A content scoring model that lives in a data science notebook.
- Right: A scoring system embedded in the CMS that flags issues before the editor hits publish.
The test is simple: How many handoffs exist between the AI's output and the action it's meant to inform? Every handoff is a point of decay. More than one, and you've built a reporting tool, not a decision tool.
The Organizational Implication
Decision proximity forces uncomfortable conversations about team structure. If the AI serves marketing decisions, it should probably report into marketing — even if the data science team built it. This threatens existing power structures. Data teams lose ownership. Engineering teams lose control. But the alternative is permanent pilot purgatory: technically sound tools that nobody uses because they're too far from the action.
When I evaluate an organization's readiness to scale AI, the first question I ask is: "Show me the workflow of the person who will act on this AI's output. How many steps exist between the model's recommendation and the human decision?" If the answer involves email, a meeting, or a separate dashboard, the initiative is already in trouble.
Condition 2: Permission Architecture
Someone must be explicitly authorized to act on AI output without seeking approval.
This is where most large organizations fail silently. They deploy AI tools, generate recommendations, and then require a human to approve every action. The approval process introduces the same bottlenecks the AI was meant to eliminate.
I call this "AI theater" — the organization gets to say it's using AI while changing nothing about how decisions flow. The AI becomes an expensive advisor that everyone ignores when it's inconvenient.
The Permission Problem Is a Trust Problem
At its root, permission architecture is about answering: "What is this AI allowed to do without asking?"
Most organizations never answer this question explicitly. Instead, they default to "nothing" — every AI recommendation requires human validation. This feels safe. It also guarantees that the AI will never operate at the speed or scale that justifies its existence.
Permission architecture requires defining three tiers:
- Autonomous actions: Decisions the AI can execute without human review. These should be low-risk, high-frequency, and reversible. Example: adjusting bid modifiers within a defined range, personalizing email subject lines, routing support tickets.
- Assisted actions: Decisions where the AI recommends and a specific individual (not a committee) approves. Approval must happen within a defined time window. If no decision is made, the AI's recommendation stands. Example: content publication, budget reallocation above threshold, new audience segment activation.
- Escalated actions: Decisions that require senior review. These should be rare and clearly defined. If more than 20% of an AI's outputs require escalation, the permission architecture is too restrictive to produce value.
The Named Decision-Maker Requirement
For every AI-generated recommendation, there must be a single named person who is authorized to act on it. Not a team. Not a committee. Not "leadership." One person with a name, a title, and the explicit authority to say yes or no within 24 hours.
If you cannot name that person for every output your AI produces, you don't have a permission architecture. You have a suggestion engine that everyone can politely ignore.
Why This Is Harder Than It Sounds
Building permission architecture means writing down things most organizations prefer to leave ambiguous. Who actually decides campaign creative? Who owns pricing changes? Who can kill an underperforming initiative without consensus?
AI forces clarity because machines can't operate on ambiguity. A human can "read the room" and figure out that even though their title says they own the decision, they actually need three people to agree. An AI can't navigate that. It needs explicit rules. Building those rules surfaces every unresolved organizational tension. (See also: The Voice Anchor Sheet.)
This is why many AI initiatives stall at the permission stage. The technology works. The integration works. But nobody is willing to write down who gets to act on what the AI says — because writing it down means confronting power dynamics that everyone has spent years carefully avoiding.
Condition 3: Measurement Specificity
You must define what "working" means at week 1, month 1, month 3, and month 6 — and these definitions must be different at each stage.
The most common way AI initiatives die is measurement mismatch. Leadership expects revenue impact in month two. The team knows the system needs six months of data to produce reliable outputs. Nobody reconciles these timelines. By month three, the initiative is "underperforming" against expectations it was never designed to meet.
The Temporal Measurement Framework
Effective AI measurement requires different metrics at different stages. These aren't arbitrary milestones — they reflect how machine learning systems actually mature.
Week 1-2: Integration metrics. Is the system receiving data? Is it producing outputs? Are those outputs reaching the decision-maker? You're not measuring quality yet. You're measuring whether the plumbing works. If the AI isn't integrated into the workflow (Condition 1) and nobody has permission to act on it (Condition 2), you'll discover that here.
Month 1: Adoption metrics. Are the designated decision-makers actually looking at AI outputs? Are they acting on recommendations? What percentage of recommendations are accepted, modified, or ignored? This isn't about the AI's accuracy — it's about whether the human-AI interface functions. High ignore rates signal a permission architecture problem, not a model problem.
Month 3: Learning metrics. Is the AI's accuracy improving? Are the recommendations getting more specific? Is the feedback loop between action and outcome closing? This is where you measure whether the system is learning from the decisions made in its name. If accuracy is flat, you likely have a data proximity issue — the AI isn't seeing the outcomes of its own recommendations.
Month 6: Impact metrics. Only now should you measure business outcomes. Revenue. Cost reduction. Speed improvement. Conversion rates. And even at this stage, you should measure relative to a control group, not absolute targets set before the system existed.
The Dashboard Problem
Most organizations build a single dashboard for their AI initiative and populate it with impact metrics from day one. The AI team spends its first three months explaining why the numbers look bad instead of doing the work that would make them look good.
The alternative: build four dashboards (or four views within one). Each is relevant at its stage. Leadership sees only the metrics appropriate to the current phase. This requires educating leadership on how ML systems mature — which requires the organizational honesty described in Condition 4.
The Metric Escalation Commitment
Before launch, get written agreement from the executive sponsor on three things:
- What metrics matter at each stage (defined above).
- What thresholds constitute "working" vs. "failing" at each stage.
- That impact metrics will not be used to evaluate the initiative before month 6.
If you can't get that commitment in writing, the initiative will be judged by standards it cannot meet. And it will die on schedule, around month three, when someone asks "what's the ROI?" and the honest answer is "we don't know yet, by design."
Condition 4: Institutional Honesty
Leadership must be willing to kill projects that feel good but don't perform — and fund projects that feel risky but show signal.
This is the condition that no framework can give you. It's cultural. And its absence kills more AI initiatives than bad data or wrong vendors.
What Institutional Dishonesty Looks Like
You'll recognize it in these patterns:
- The perpetual pilot: An initiative that never graduates to production but never gets killed. It exists in limbo because canceling it would require admitting the original thesis was wrong.
- The vanity metric: An AI system that optimizes for a number that looks good in board decks but doesn't connect to business value. Everyone knows this, but the metric is politically useful so nobody challenges it.
- The innovation theater: An AI project whose primary purpose is to signal modernity to the board, investors, or press. It's never intended to produce business impact. It's intended to produce a slide.
- The consensus trap: A decision that requires so many stakeholders to agree that the AI's recommendation is diluted into meaninglessness before it reaches execution.
The Kill Criteria Test
Before any AI initiative launches, it should have explicit kill criteria. Not "we'll evaluate at the end of the quarter" — that's too vague. Specific conditions under which the project will be terminated, resources reallocated, and the team redeployed without stigma.
Good kill criteria look like:
- "If adoption rate is below 40% at week 6, we stop and diagnose."
- "If the model's recommendation acceptance rate doesn't exceed 50% by month 2, we revisit the permission architecture."
- "If we cannot demonstrate measurable improvement over the baseline by month 5, we reallocate budget to a different use case."
Kill criteria require institutional honesty because they force the organization to admit failure early and publicly. Most corporate cultures punish this. Which is why most AI initiatives die slowly and expensively rather than quickly and cheaply.
The Sunk Cost Immunity
The organizations that scale AI successfully share one trait: they treat AI investments as experiments, not commitments. An experiment that produces a negative result isn't a failure — it's information. A commitment that produces a negative result is a disaster.
If your leadership treats every AI initiative as a commitment that must succeed, your teams will never report honestly. They'll hide bad results, extend timelines, and find creative metrics that make things look better than they are. The initiative will die eventually — it'll just cost three times more and take twice as long.
The diagnostic question: "When was the last time this organization killed a funded initiative in its first 90 days based on data?" If the answer is "never" or "I can't remember," Condition 4 is not met.
The Conditions Are Interdependent
These four conditions aren't a checklist to complete sequentially. They form a system. Each one depends on and reinforces the others.
- Decision proximity without permission architecture creates frustration — the AI is right there, but nobody can act on it.
- Permission architecture without measurement specificity creates chaos — people are acting on AI outputs with no way to know if those actions are working.
- Measurement specificity without institutional honesty creates theater — you'll have beautiful dashboards that nobody uses to make hard decisions.
- Institutional honesty without decision proximity creates expensive consulting reports — leadership is willing to face reality, but the AI is too far from the action to produce actionable reality.
All four must be present simultaneously. This is why AI scaling is hard. It's not a technology problem. It's a four-dimensional organizational design problem being addressed one dimension at a time.
A Pre-Scale Diagnostic
Before you fund the next phase of any AI initiative, answer these questions honestly:
Decision Proximity
- How many handoffs exist between the AI's output and the human decision it informs?
- Is the AI embedded in the decision-maker's daily workflow tool?
- Does the AI see the outcomes of decisions made from its recommendations?
Permission Architecture
- Can you name the single person authorized to act on each type of AI output?
- What percentage of the AI's outputs can be executed without committee approval?
- Is there a defined time window for decisions, with a default if no action is taken?
Measurement Specificity
- Do you have different success metrics for week 1, month 1, month 3, and month 6?
- Has the executive sponsor committed in writing to stage-appropriate evaluation?
- Are you measuring adoption and learning before you measure impact?
Institutional Honesty
- Does the initiative have explicit, time-bound kill criteria?
- When did this organization last kill a funded project within 90 days?
- Are teams rewarded for surfacing negative results early?
If you can't answer "yes" to at least three questions in each category, you aren't ready to scale. You're ready to build another impressive pilot that dies on schedule.
What To Do If You're Not Ready
Not being ready isn't failure. It's information. Most organizations need 60-90 days of intentional preparation before an AI initiative can scale. That preparation isn't technical — it's organizational.
For Decision Proximity gaps: Map the workflow of every person who will receive AI output. Identify every handoff. Eliminate at least half of them before launch. If this requires changing reporting lines, change them.
For Permission Architecture gaps: Run a two-week exercise where you document every decision the AI would make. For each one, write down who is currently authorized to make that decision, how long it takes, and what approval chain exists. Then design the architecture you need — not the one you have.
For Measurement Specificity gaps: Build the four-stage measurement plan. Present it to leadership. Get explicit sign-off on the timeline. If leadership won't agree to stage-appropriate evaluation, you have a Condition 4 problem, not a Condition 3 problem.
For Institutional Honesty gaps: This is the hardest to fix because it's cultural. Start small: create a "pre-mortem" practice for the AI initiative. Before launch, ask the team to describe all the ways it could fail. Then ask leadership which of those failure modes they're willing to accept and which would trigger a kill decision. Write it down. Make it public within the team. This doesn't fix culture, but it creates a reference point that makes honesty slightly easier when the moment arrives.
The Real AI Roadmap
Most AI roadmaps are technology deployment plans. They describe what gets built and when. They ignore the organizational conditions that determine whether what gets built actually survives.
A real AI roadmap is an organizational readiness plan. It asks: "What must be true about how this company makes decisions, distributes authority, measures progress, and handles failure before this technology can produce durable value?"
The answer to that question is almost never "better data" or "more compute" or "a different vendor." It's almost always: "We need to make explicit the things we've been leaving ambiguous, and we need to give specific people specific authority to do specific things based on what the AI tells them."
That's not a technology transformation. It's an organizational one that happens to be triggered by technology. And until you treat it that way, your pilots will keep dying.